
Nvidia übermittelt seine ersten MLPerf-Ergebnisse für seine selbst entwickelte CPU+GPU und seine L4-GPUs.
Nvidia gab heute bekannt, dass es seine ersten Benchmark-Ergebnisse für seinen Grace Hopper CPU+GPU-Superchip und seine L4-GPU-Beschleuniger an die neueste Version von MLPerf übermittelt hat, einem branchenüblichen KI-Benchmark, der gleiche Wettbewerbsbedingungen für die Messung der KI-Leistung bieten soll unterschiedliche Arbeitsbelastungen.
Die heutige Runde der Benchmark-Ergebnisse markiert zwei bemerkenswerte Neuerungen für den MLPerf-Benchmark: Die Hinzufügung eines neuen GPT-J-Inferenz-Benchmarks für das Large Language Model (LLM) und eines überarbeiteten Empfehlungsmodells. Nvidia behauptet, dass der Grace Hopper Superchip im GPT-J-Benchmark bis zu 17 % mehr Inferenzleistung liefert als eine seiner marktführenden H100-GPUs und dass seine L4-GPUs bis zu 6-mal so viel Leistung liefern wie die Xeon-CPUs von Intel.
Die Branche schreitet mit rasender Geschwindigkeit voran und entwickelt sich rasant zu neueren KI-Modellen und leistungsfähigeren Implementierungen. Ebenso wird der MLPerf-Benchmark, der vom MLCommons-Gremium verwaltet wird, mit seiner neuen Version 3.1 ständig weiterentwickelt, um die sich verändernde Natur der KI-Landschaft besser widerzuspiegeln.
GPT-J 6B, ein Zusammenfassungsmodell für Text, das seit 2021 in realen Workloads verwendet wird, wird jetzt in der MLPerf-Suite als Benchmark für die Messung der Inferenzleistung verwendet. Das 6-Milliarden-Parameter-LLM von GPT-J ist im Vergleich zu einigen der fortschrittlicheren KI-Modelle, wie dem 175-Milliarden-Parameter-GPT-3, eher leichtgewichtig, eignet sich aber gut für die Rolle eines Inferenz-Benchmarks. Dieses Modell fasst Textblöcke zusammen und arbeitet sowohl im Online-Modus, der latenzempfindlich ist, als auch im Offline-Modus, der durchsatzintensiv ist. Die MLPerf-Suite verwendet jetzt auch ein größeres DLRM-DCNv2-Empfehlungsmodell mit der doppelten Parameteranzahl, einen größeren Multi-Hot-Datensatz und einen schichtübergreifenden Algorithmus, der reale Umgebungen besser abbildet.

Vor diesem Hintergrund können wir hier einige der Leistungsansprüche von Nvidia sehen. Beachten Sie, dass Nvidia diese Benchmarks selbst an MLCommons übermittelt, sodass es sich wahrscheinlich um hochgradig abgestimmte Best-Case-Szenarien handelt. Nvidia weist außerdem gerne darauf hin, dass es das einzige Unternehmen ist, das Benchmarks für jedes in der MLPerf-Suite verwendete KI-Modell vorlegt, was eine objektiv wahre Aussage ist. Einige Unternehmen fehlen ganz, wie AMD, oder reichen nur einige ausgewählte Benchmarks ein, wie Intel mit Habana und Google mit seiner TPU. Die Gründe für den Mangel an Einsendungen variieren je nach Unternehmen, aber es wäre schön, wenn mehr Konkurrenten in den MLPerf-Ring eintreten würden.
Nvidia hat sein erstes MLPerf-Ergebnis für den GH200 Grace Hopper Superchip vorgelegt und dabei hervorgehoben, dass die Kombination aus CPU und GPU 17 % mehr Leistung liefert als eine einzelne H100-GPU. Oberflächlich betrachtet ist das überraschend, wenn man bedenkt, dass die GH200 das gleiche Silizium wie die H100-CPU verwendet, aber wir erklären weiter unten, warum. Natürlich übertrafen die mit acht H100 ausgestatteten Systeme von Nvidia den Grace Hopper Superchip und übernahmen in jedem Inferenztest die Führung.
Zur Erinnerung: Der Grace Hopper Superchip kombiniert eine Hopper-GPU und die Grace-CPU auf derselben Platine und stellt eine C2C-Verbindung (detaillierter Einblick hier) mit 900 GB/s Durchsatz zwischen den beiden Einheiten bereit und bietet somit die 7-fache Bandbreite eines typischen PCIe Verbindung für CPU-zu-GPU-Datenübertragungen, wodurch die verfügbare Speicherbandbreite des GH200 erhöht wird, ergänzt durch einen kohärenten Speicherpool, der 96 GB HBM3-Speicher und 4 TB/s GPU-Speicherbandbreite umfasst. Im Gegensatz dazu verfügt der im HGX getestete Vergleichs-H100 nur über 80 GB HBM3 (Grace Hopper-Modelle der nächsten Generation werden im zweiten Quartal 2024 über 144 GB 1,7-mal schnelleres HBM3e verfügen).
Nvidia wirbt außerdem mit einer dynamischen Power-Shifting-Technologie namens Automatic Power Steering, die das Leistungsbudget zwischen CPU und GPU dynamisch ausgleicht und das Spillover-Budget auf die Einheit steuert, die am meisten ausgelastet ist. Diese Technologie wird in vielen konkurrierenden modernen CPU+GPU-Kombinationen verwendet, ist also nicht neu, ermöglicht es der GPU auf dem Grace Hopper Superchip jedoch, aufgrund der Leistungsverlagerung von einem höheren Budget für die Leistungsabgabe zu profitieren als im HGX die Grace-CPU – das ist auf einem Standardserver nicht möglich. Das vollständige CPU+GPU-System lief mit einer TDP von 1000 W.
Die meisten Schlussfolgerungen werden weiterhin auf CPUs ausgeführt, was sich in Zukunft ändern könnte, da größere Modelle häufiger vorkommen; Der Ersatz von CPUs für diese Arbeitslasten durch kleine GPUs mit geringem Stromverbrauch wie dem L4 ist für Nvidia von größter Bedeutung, da dies den Umsatz in hohen Stückzahlen ankurbeln würde. Diese Runde der MLPerf-Einreichungen umfasst auch die ersten Ergebnisse für Nvidias L4-GPUs, wobei die inferenzoptimierte Karte im GPT-J-Inferenzbenchmark die sechsfache Leistung eines einzelnen Xeon 9480 liefert, obwohl sie in einer Karte mit schlankem Formfaktor nur 72 W verbraucht erfordert keinen Hilfsstromanschluss.
Nvidia gibt außerdem eine bis zu 120-fache Leistung bei einer Video+KI-Dekodierung-Inferenz-Kodierung im Vergleich zu CPUs an, indem es die Leistung von acht L4-GPUs im Vergleich zu zwei Xeon 8380s-CPUs der vorherigen Generation misst, was etwas einseitig ist. Dies soll wahrscheinlich ein direkter Vergleich der schieren Menge an Rechenleistung sein, die in einem einzigen Gehäuse untergebracht werden kann. Dennoch ist es bemerkenswert, dass Quad-Socket-Server verfügbar sind, auch wenn sie für diese Aufgabe nicht optimal geeignet sind und neuere Xeon-Chips in diesem Test wahrscheinlich etwas besser abschneiden würden. Die Testkonfiguration finden Sie im Kleingedruckten unten auf der Folie. Achten Sie also unbedingt auf diese Details.
Schließlich reichte Nvidia auch Benchmarks seiner Jetson-Orin-Roboterchips ein, die einen 84-prozentigen Anstieg des Inferenzdurchsatzes zeigten, der größtenteils auf Verbesserungen der Software zurückzuführen ist.
Es ist wichtig, sich daran zu erinnern, dass in der realen Welt jedes KI-Modell als Teil einer längeren Reihe von Modellen ausgeführt wird, die in einer KI-Pipeline ausgeführt werden, um eine bestimmte Aufgabe oder Aufgabe zu erfüllen. Die obige Abbildung von Nvidia verdeutlicht dies gut: Acht verschiedene KI-Modelle werden vor der Fertigstellung für eine Abfrage ausgeführt – und es ist nicht ungewöhnlich, dass diese Art von KI-Pipelines bis zu 15 Netzwerke erweitern, um eine einzelne Abfrage zu erfüllen. Dies ist ein wichtiger Kontext, da sich die oben genannten durchsatzorientierten Benchmarks in der Regel auf die Ausführung eines einzelnen KI-Modells mit hoher Auslastung konzentrieren, im Gegensatz zur realen Pipeline, die deutlich mehr Vielseitigkeit erfordert, da mehrere KI-Modelle nacheinander ausgeführt werden, um eine bestimmte Aufgabe zu erfüllen Aufgabe.
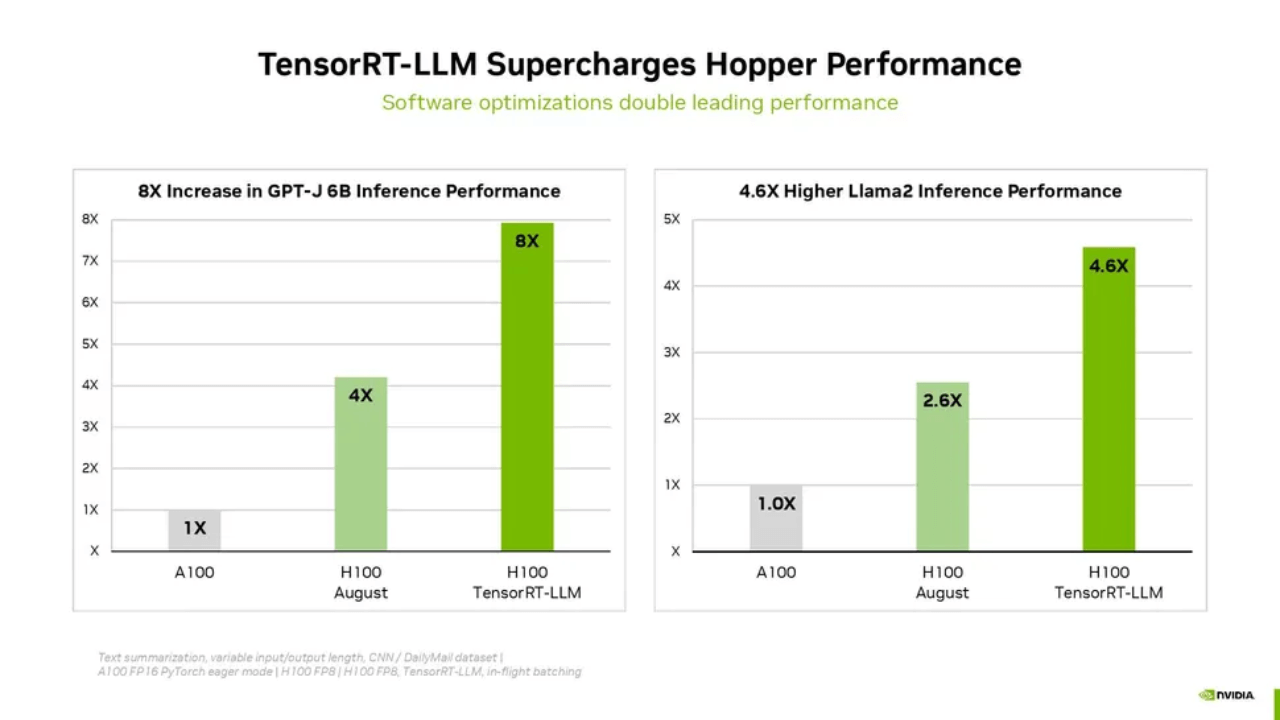
Nvidia gab letzte Woche außerdem bekannt, dass seine TensorRT-LLM-Software für generative KI-Workloads eine optimierte Leistung bei Inferenz-Workloads liefert und bei Verwendung auf seinen H100-GPUs insgesamt mehr als die doppelte Leistung liefert, ohne zusätzliche Kosten. Nvidia hat kürzlich Details zu dieser Software bereitgestellt, die Sie hier nachlesen können, und weist darauf hin, dass diese Software zur Inferenzsteigerung für diese Ergebnisrunde noch nicht bereit war; MLCommons erfordert eine Vorlaufzeit von 30 Tagen für MLPerf-Einreichungen und TensorRT-LLM war zu diesem Zeitpunkt nicht verfügbar. Das bedeutet, dass Nvidias erste Runde der MLPerf-Benchmarks mit der nächsten Einreichungsrunde eine enorme Verbesserung erfahren dürfte.





