
Ein neues Projekt zielt darauf ab, die Qualität von KI-LLM-Chatbots zu bewerten.
Vectara hat eine Rangliste für KI-Halluzinationen veröffentlicht, in der verschiedene führende KI-Chatbots nach ihrer Fähigkeit, nicht zu halluzinieren, eingestuft werden. Die Rangliste soll offensichtlich aufzeigen, inwieweit die verschiedenen öffentlichen großen Sprachmodelle (LLMs) halluzinieren, aber was bedeutet dies, warum ist es wichtig, und wie wird es gemessen?
Eine der Eigenschaften von KI-Chatbots, die uns misstrauisch gemacht haben, ist ihre Tendenz, zu „halluzinieren“ – Fakten zu erfinden, um Lücken zu füllen. Ein öffentlichkeitswirksames Beispiel dafür war die Anwaltskanzlei Levidow, Levidow & Oberman, die in Schwierigkeiten geriet, nachdem sie „nicht existierende Gerichtsgutachten mit gefälschten Zitaten und Zitaten, die vom Tool für künstliche Intelligenz ChatGPT erstellt wurden, eingereicht hatte.“ Es wurde festgestellt, dass gefälschte Rechtsentscheidungen wie Martinez v. Delta Air Lines einige Züge aufweisen, die mit tatsächlichen Gerichtsentscheidungen übereinstimmen, aber bei näherer Betrachtung wurden Teile von „Kauderwelsch“ entdeckt.
Wenn man über den potenziellen Einsatz von LLMs in Bereichen wie Gesundheit, Industrie, Verteidigung usw. nachdenkt, ist es eindeutig zwingend erforderlich, KI-Halluzinationen als Teil jeder laufenden Entwicklung auszumerzen. Um ein praktisches Beispiel für eine halluzinierende KI unter kontrollierten Referenzbedingungen zu beobachten, beschloss Vectara, einige Tests mit elf öffentlichen LLMs durchzuführen:
- Geben Sie den LLMs einen Stapel von über 800 kurzen Referenzdokumenten.
- Bitten Sie die LLMs, sachliche Zusammenfassungen der Dokumente zu geben, wie durch eine Standardaufforderung angewiesen.
- Füttern Sie die Antworten mit einem Modell, das die Einführung von Daten erkennt, die nicht in der/den Quelle(n) enthalten waren.
Die verwendete Eingabeaufforderung lautete wie folgt: Du bist ein Chatbot, der Fragen anhand von Daten beantwortet. Sie müssen sich an die Antworten halten, die ausschließlich aus dem Text in der vorgegebenen Passage hervorgehen. Ihnen wird die Frage gestellt: „Geben Sie eine kurze Zusammenfassung des folgenden Textes, die die wichtigsten beschriebenen Informationen enthält. <PASSAGE>‘
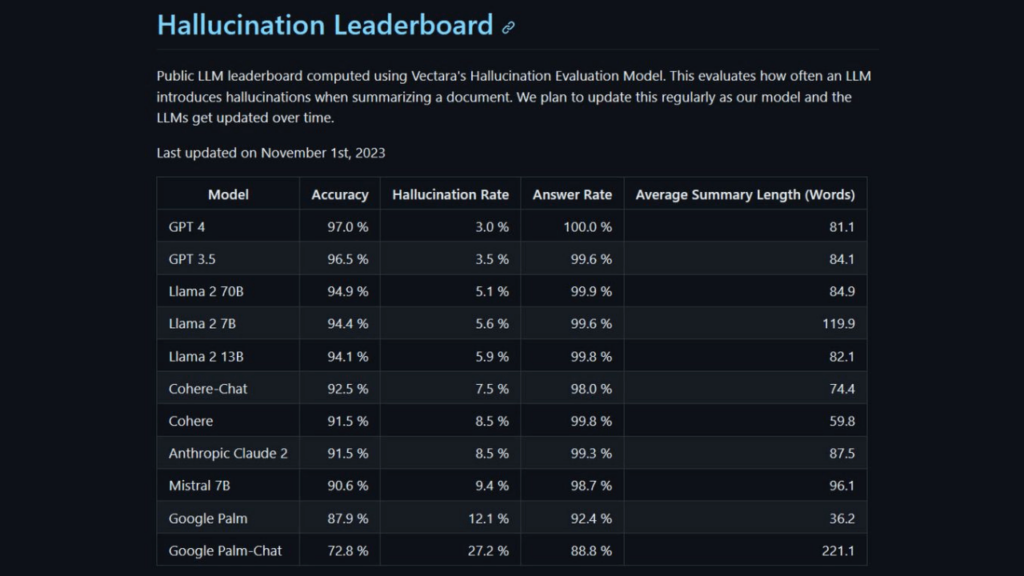
Die Rangliste wird in regelmäßigen Abständen aktualisiert, um mit der Verbesserung bestehender und der Einführung neuer und verbesserter LLM Schritt zu halten. Im Moment zeigen die ersten Daten aus dem Halluzinationsbewertungsmodell von Vectara, wie die LLMs abschneiden.
GPT-4 schnitt mit der niedrigsten Halluzinationsrate und der höchsten Genauigkeit am besten ab – wir müssen uns fragen, ob es Levidow, Levidow & Oberman aus den Schwierigkeiten hätte heraushalten können. Am anderen Ende der Tabelle schnitten zwei Google LLMs deutlich schlechter ab. Eine Halluzinationsrate von über 27 % für Google Palm-Chat deutet darauf hin, dass seine sachlichen Zusammenfassungen von Referenzmaterial bestenfalls als unzuverlässig eingestuft werden. Die Antworten von Palm-Chat scheinen nach den Messungen von Vectara durchweg mit halluzinatorischen Trümmern übersät zu sein.
Im FAQ-Bereich seiner GitHub-Seite erklärt Vectara, dass es sich aufgrund von Überlegungen wie dem Umfang der Tests und der Konsistenz der Bewertung für die Verwendung eines Modells zur Bewertung der jeweiligen LLMs entschieden hat. Es behauptet auch, dass „die Erstellung eines Modells zur Erkennung von Halluzinationen viel einfacher ist als die Erstellung eines Modells, das frei von Halluzinationen ist.“
Die Tabelle hat in ihrer jetzigen Form bereits einige hitzige Diskussionen in den sozialen Medien ausgelöst. Sie könnte sich auch zu einer nützlichen Referenz oder einem Benchmark entwickeln, den Menschen, die LLMs für ernsthafte – nicht-kreative – Aufgaben einsetzen wollen, genau unter die Lupe nehmen werden.
In der Zwischenzeit freuen wir uns darauf, dass Elon Musks kürzlich angekündigtes Grok mit diesem AI Hallucination Evaluation Model gemessen wird. Der Chatbot ging vor 10 Tagen in der Beta-Version an den Start, mit einer offensichtlichen Entschuldigung für Ungenauigkeiten und damit zusammenhängende Fehler, wobei seine Schöpfer Grok als humorvoll und sarkastisch beschreiben.





