
AMD hat seinen KI-Beschleuniger Instinct MI300X und den Instinct MI300A, die weltweit erste APU für Rechenzentren, während seines Advancing AI-Events hier in San Jose, Kalifornien, vorgestellt, um vom boomenden Markt für generative KI und HPC zu profitieren. AMD hat sein MI300 Lineup mit den fortschrittlichsten Produktionstechnologien geschmiedet, die jemals in die Massenproduktion gepresst wurden. Dabei wurden neue Techniken wie das „3.5D“-Packaging eingesetzt, um zwei Multi-Chip-Giganten zu produzieren, die laut AMD eine Nvidia-übertreffende Leistung bei einer Vielzahl von KI-Workloads bieten. AMD gibt keine Preise für sein neues exotisches Silizium bekannt, aber die Produkte werden jetzt an eine breite Palette von OEM-Partnern ausgeliefert.
Der Instinct MI300 ist ein bahnbrechendes Design – die APU für Rechenzentren vereint insgesamt 13 Chiplets, von denen viele in 3D gestapelt sind, zu einem Chip mit 24 Zen 4 CPU-Kernen, der mit einer CDNA 3-Grafikengine und acht HBM3-Stapeln verschmolzen ist. Insgesamt wiegt der Chip 153 Milliarden Transistoren und ist damit der größte Chip, den AMD je hergestellt hat. AMD behauptet, dass dieser Chip in einigen Workloads bis zu viermal mehr Leistung als Nvidias H100-GPUs liefert und wirbt damit, dass er die doppelte Leistung pro Watt bietet.
AMD behauptet, dass seine Instinct MI300X GPU bis zu 1,6-mal mehr Leistung als die Nidia H100 bei KI-Inferenz-Workloads liefert und eine ähnliche Leistung bei Trainingsarbeiten bietet, wodurch die Industrie eine dringend benötigte Hochleistungsalternative zu Nvidias GPUs erhält. Darüber hinaus verfügen diese Beschleuniger über mehr als die doppelte HBM3-Speicherkapazität als Nvidias GPUs – unglaubliche 192 GB pro Stück – und ermöglichen es den MI300X-Plattformen, mehr als die doppelte Anzahl von LLMs pro System zu unterstützen sowie größere Modelle als Nvidias H100 HGX auszuführen.
AMD Instinct MI300X
Der MI300X stellt den Höhepunkt der Chiplet-basierten Design-Methode von AMD dar. Er vereint acht 12-Hi-Stapel von HBM3-Speicher mit acht 3D-gestapelten 5-nm-CDNA-3-GPU-Chiplets, genannt XCD, auf vier darunter liegenden 6-nm-E/A-Dies, die mit der inzwischen ausgereiften Hybrid-Bonding-Technik von AMD verbunden sind.
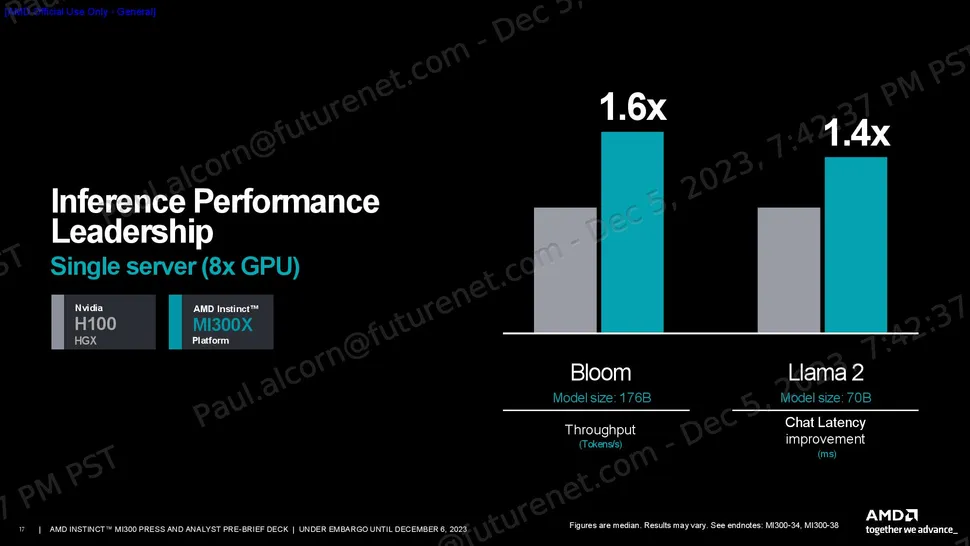
Wie immer sollten wir Hersteller-Benchmarks mit Vorsicht genießen. AMD teilte eine Reihe von Leistungskennzahlen mit, die zeigen, dass der Spitzenwert des theoretischen FP64- und FP32-Vektormatrix-Durchsatzes des H100 für HPC-Workloads bis zu 2,4-mal höher ist als der des H100 und der Spitzenwert des theoretischen TF32-, FP16-, BF16-, FP8- und INT8-Durchsatzes für KI-Workloads bis zu 1,3-mal höher ist, und das alles ohne Sparsity (der MI300X unterstützt jedoch Sparsity).
Die enorme Speicherkapazität und Bandbreite des MI300X sind ideal für Inferencing. AMD verwendete ein Flash Attention 2-Modell mit 176 Milliarden Parametern, um einen 1,6-fachen Leistungsvorteil gegenüber der Nvidia H100 beim Token/s-Durchsatz zu erzielen, und ein Llama 2-Modell mit 70 Milliarden Parametern, um einen 1,4-fachen Vorteil bei der Chat-Latenz (gemessen vom Beginn bis zum Ende der 2K-Sequenzlänge/128 Token) zu erzielen.
Die MI300X-Plattform von AMD lieferte bei einer MPT-Trainingslast mit 30 Milliarden Parametern ungefähr die gleiche Leistung wie das H100 HGX-System. Stattdessen werden bei diesem Test Gruppen von acht Beschleunigern gegeneinander antreten, so dass die Fähigkeiten auf Plattformebene eher zu einem begrenzenden Faktor werden. In jedem Fall ist dies die Art von Leistung, die in einer von Nvidias GPU-Engpässen geplagten Branche schnell auf Interesse stoßen wird.
Apropos Plattform: AMD behauptet auch, dass die MI300X-Plattform aufgrund ihrer Speicherkapazität bis zu doppelt so viele Trainingsmodelle mit 30B-Parametern und Inferenzmodelle mit 70B-Parametern hosten kann wie das H100-System. Darüber hinaus kann die MI300X-Plattform bis zu 70B-Trainings- und 290B-Parameter-Inferenzmodelle unterstützen, die beide doppelt so groß sind wie die Modelle, die von der H100 HGX unterstützt werden.
Natürlich werden die kommenden H200-GPUs von Nvidia in Bezug auf Speicherkapazität und Bandbreite wettbewerbsfähiger sein, während die Rechenleistung mit der der bestehenden H100 vergleichbar sein wird. Nvidia wird mit der Auslieferung der H200 erst im nächsten Jahr beginnen, so dass ein Vergleich mit der MI300X noch auf sich warten lässt.
AMD Instinct MI300A
Der AMD Instinct MI300A ist die weltweit erste APU für Rechenzentren, was bedeutet, dass er sowohl eine CPU als auch eine GPU in einem Gehäuse vereint. Damit steht er in direkter Konkurrenz zu Nvidias Grace Hopper Superchips, bei denen CPU und GPU in separaten Chip-Paketen untergebracht sind, die im Tandem arbeiten.
Der MI300A verwendet dasselbe grundlegende Design und dieselbe Methodik wie der MI300X, ersetzt aber drei 5nm Core Compute Die (CCD) mit jeweils acht Zen 4 CPU-Kernen, wie sie auch in den EPYC- und Ryzen-Prozessoren zu finden sind, und verdrängt damit zwei der XCD-GPU-Chiplets.

Damit verfügt der MI300A über 24 Threaded-CPU-Kerne und 228 CDNA-3-Recheneinheiten, die sich auf sechs XCD-GPU-Chiplets verteilen. Wie beim MI300X sind alle Compute Chiplets in 3D gestapelt, wobei hybrides Bonding mit vier darunter liegenden I/O Dies (IOD) verwendet wird, um eine weitaus bessere Bandbreite, Latenz und Energieeffizienz zu ermöglichen, als dies mit Standard-Chip-Packaging-Techniken möglich ist.
AMD hat die Speicherkapazität durch die Verwendung von acht 8-Hi-HBM3-Stapeln anstelle der acht 12-Hi-Stapel, die für den MI300X verwendet wurden, reduziert, wodurch sich die Kapazität von 192 GB auf 128 GB verringert. Die Speicherbandbreite bleibt jedoch bei 5,3 TB/s. AMD sagt uns, dass die Entscheidung, die Speicherkapazität zu reduzieren, nicht auf Leistungs- oder Wärmebeschränkungen zurückzuführen ist; stattdessen wird der Chip für die angestrebten HPC- und KI-Workloads maßgeschneidert. Unabhängig davon sind die Kapazität von 128 GB und der Durchsatz von 5,3 TB/s immer noch 1,6-mal höher als bei der H100 SXM GPU von Nvidia.
Der MI300A hat eine Standard-TDP von 350 W, ist aber auf bis zu 760 W konfigurierbar. AMD verteilt die Leistung dynamisch zwischen dem CPU- und dem GPU-Teil des Chips, je nach Nutzung, und optimiert so die Leistung und Effizienz. AMD setzt clevere Wiederverwendung ein, wo immer es möglich ist: Der MI300A passt in AMDs Standard-Sockel LGA6096, genau wie die EPYC Genoa-Prozessoren, aber die SH5-Version dieses Sockels ist elektrisch nicht kompatibel mit AMDs EPYC-Prozessoren, die SP5 verwenden.




